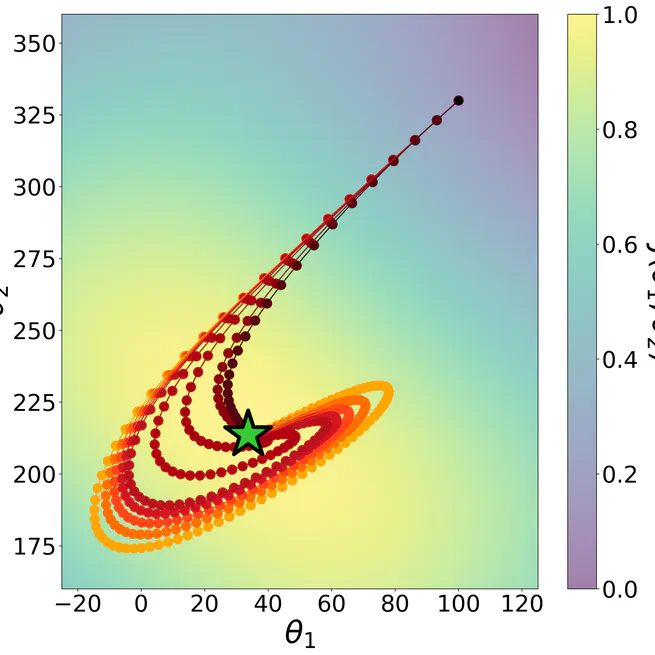
K-Level Policy Gradients for Multi-Agent Reinforcement Learning
Actor-critic algorithms for deep multi-agent reinforcement learning (MARL) typically employ a policy update that responds to the current strategies of other agents. While being straightforward, this approach does not account for the updates of other agents at the same update step, resulting in miscoordination. In this paper, we introduce the K-Level Policy Gradient (KPG), a method that recursively updates each agent against the updated policies of other agents, speeding up the discovery of effective coordinated policies. We theoretically prove that KPG with finite iterates achieves monotonic convergence to a local Nash equilibrium under certain conditions. We provide principled implementations of KPG by applying it to the deep MARL algorithms MAPPO, MADDPG, and FACMAC. Empirically, we demonstrate superior performance over existing deep MARL algorithms in StarCraft II and multi-agent MuJoCo.
Sep 15, 2025
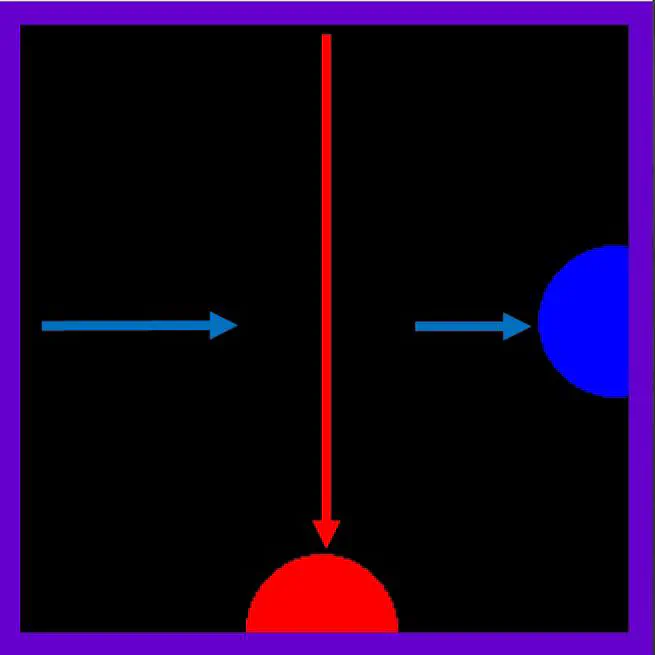
Deep Learning Agents Trained For Avoidance Behave Like Hawks And Doves
We present heuristically optimal strategies expressed by deep learning agents playing a simple avoidance game. We analyse the learning and behaviour of two agents within a symmetrical grid world that must cross paths to reach a target destination without crashing into each other or straying off of the grid world in the wrong direction. The agent policy is determined by one neural network that is employed in both agents. Our findings indicate that the fully trained network exhibits behaviour similar to that of the game Hawks and Doves, in that one agent employs an aggressive strategy to reach the target while the other learns how to avoid the aggressive agent.
Mar 14, 2025